
In disem Beitrag ist beschrieben, wie man eine Webseite im IPFS speichert und über einen Domain abrufbar macht.
Was ist das IPFS
Das Interplanetarische Filesystem (IPFS) ist die Basis für das neue dezentrale Web 3. Der Content wird nicht mehr auf zentralen Servern gehostet, sondern verteilt über alle Teilnehmer des neuen Webs.
Somit können Inhalte nicht mehr “abgeschaltet” werden oder durch einen Angriff auf einen zentralen Server abhanden kommen.
Das IPFS speichert statische Inhalte. Dynamische webseiten - wie sie heute üblich sind - werden durch den Einatz von JavaScript im Browser realisiert. Solche Webseiten haben viele Vorteile, sind aber etwas schwerer zu programmieren.
Wenn die Webseite auf eine Datenbank zurückgreifen muss, geht das auch dezentral. Dann kommen zusätzlich so genannte “Smart Contracts” in einer Blockchain zum Einsatz (z.B. Etehereum).
Alle Dateien, die im IPFS gespeichert werden, werden durch einen HASH-Wert addressiert, der auf Basis der Datei generiert wird. Hinter einer Adresse (einem HASH) steckt also garantiert immer dieselbe Datei. Wird sie manipuliert und neu gespeichert, so entsteht automatisch ein ganz neuer HASH-Wert und somit eine andere Adresse.
IPFS einrichten
Um selber Dinge in das IPFS laden zu können, muss man Teil des Netzes werden. Dafür installieren wir uns einen eigenen IPFS Node. Der IPFS Desktop kann hier heruntergeladen und dann installiert werden.
Darüber hinaus empfehle ich das Browser Plugin IPFS-Companion für Chrome zu installieren.
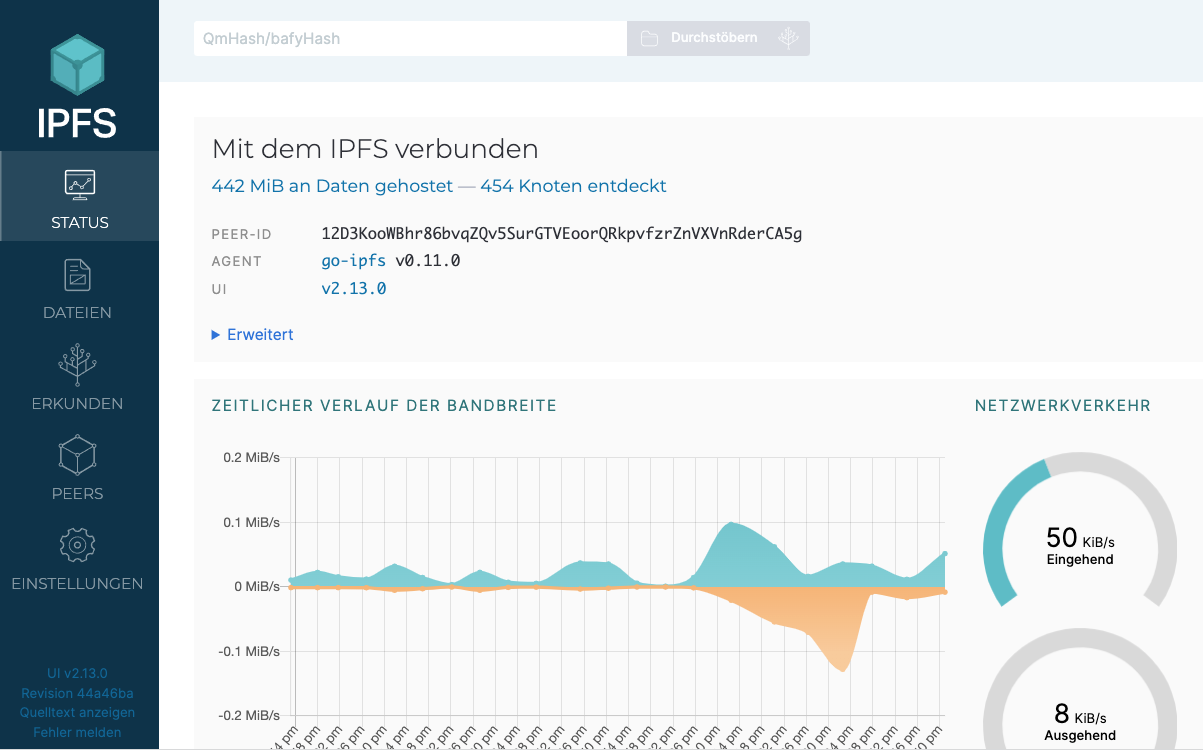
Startet man dann den IPFS Desktop, so verbindet er sich mit dem IPFS, was in der Statusanzeige auch gut zu beobachten ist:
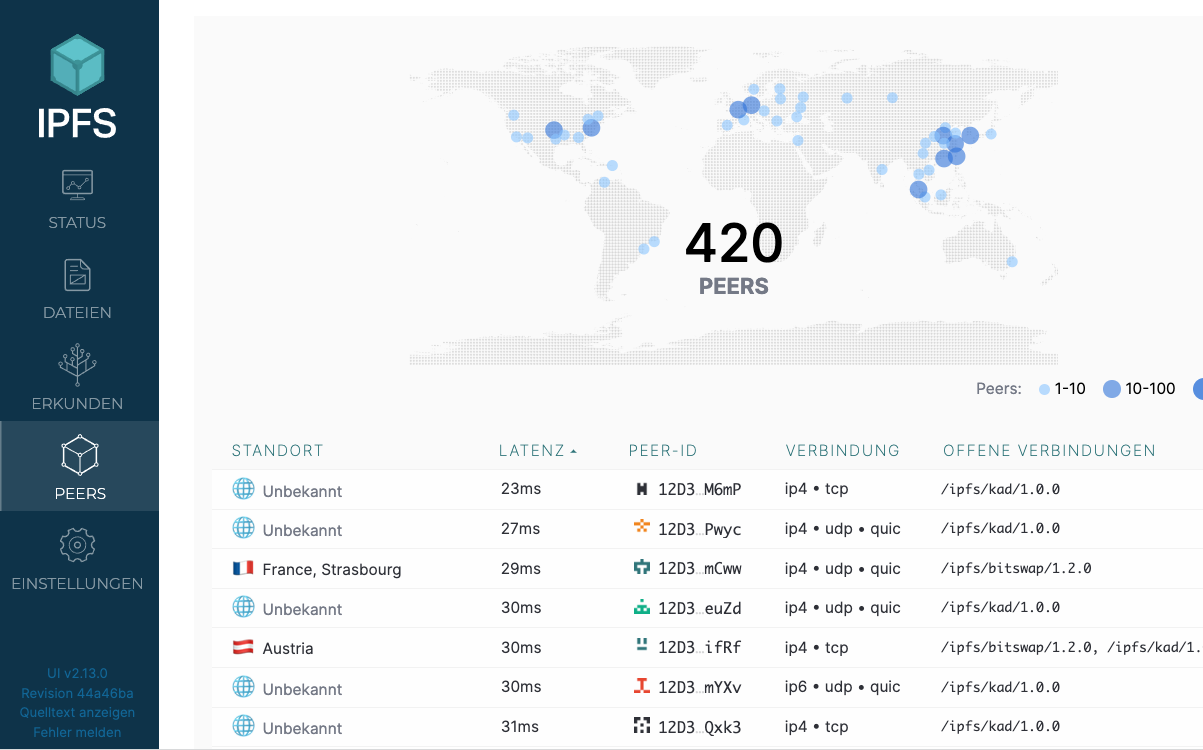
Auch kann man nachschauen, mit welchen Nodes man gerade verbunden ist:
Damit sind wir nun selber Teil des Web 3 und setellen es für alle Nutzer bereit. Dateien werden nun ganz oder teilweise auch auf unserem Rechner gespeichert, damit andere diese finden und laden können. Sofern Inhalte von Interesse sind, werden diese Häufig abgerufen und verteilen sich so über alle Nodes.
Gelöscht werden, können einmal veröffentlichte Dateien dann nicht mehr. Natürlich kann nicht unedlich viel gespeichert werden. Dateien, die wirklich niemanden interesseiren, vergisst das IPFS irgendwann auch wieder.
Was man gegen dieses Vergessen tun kann, kommt später noch.
Die Webseite für das IPFS vorbereiten
Wir wollen eine Webseite in das IPFS transferieren. Damit das geht, muss die Seite komplett statisch sein. Wir benötigen ein Verzeichnis, in dem sich eine index.html-Datei befindet. Wahrscheinlich werden in diesem Verzeichnis weitere Verzeichnisse mit Namen wie “img” oder “js” enthalten sein. Das ist alles kein Problem - wir können eine ganze Verzeichnisstruktur problemlos ins IPFS laden.
Eine mit HUGO erstelle Webseite ist beispielsweise bestens für das IPFS geeignet. Wer HUGO nicht kennt, sollte mal einen Blick darauf werfen. Für viele Anwendungen reicht HUGO absolut aus und das Leben ist damit deutlich leichter.
Alle HTTP-Links entfernen
Wir wollen unsere Seite vollständig ins IPFS laden. Dafür darf sie natürlich keine http-Links mehr enthalten. Mit einem Verweis auf Google-Fonts oder auf in einem CDN gespeichertes Bootstrap-css verlassen wir das IPFS wieder.
Also: Alle Abhängigkeiten auflösen, in dem wir solche Dateien ebenfalls lokal in unserem Ordner speichern. Die Webseite muss funktionieren, wenn wir die index.html ohne bestehende Internetverbindung im Incognito-Fenster als Datei öffnen.
Es gibt einen weiteren Fallstrick:
Ein Bild, dass man in die Webseite einbetten möchte, addressiert man womöglich über /img/testbild.png. Wird die Seite nun über ein Gateway abgerufen, so wird das Bild nicht gefunden, weil es im Verzeichnis /img des Gateways gesucht wird. Solche Bezüge müssen immer relativ zur Position der aktuellen Seite im Verzeichnisbaum sein. Befindet sich die aktuelle HTML-Seite in einem Unterverzeichnis, so ist der korrekte relative Bezug zum Bild ../img/testbild.png. Bei einer größeren Webseite ist das manuell nur noch schwer unter Kontrolle zu halten.
In HUGO existiert hier zum Glück ein Konfigurationsparameter relativeURLs = true, durch den automatisch alle URLs entdsprechend angepasst werden.
Weiterhin sollte in HUGO canonifyURLs = false gesetzt sein. Sonst werden alle Links als komplette URL mit vorangestellter Domain erzeugt.
Als leter Schritt muss noch sichergestellt werden, dass in keinem HUGO-Template .Permalink verwendet wird, sondern .RelPermalink. Das kann im Zweifel einfach durch globales Suchen und Ersetzen erreicht werden.
Danach muss die Webseite noch einmal neu generiert werden.
Das Tückische an diesem URL-Problemen ist, dass man es woöglich selber nicht bemerkt, weil man die Seite immer nur vom lokalen IPFS-Node läd.
Die Webseite ins IPFS laden
Nun sind wir so weit und können die Seite ins IPFS laden. Dafür öffnen wir wieder den IPFS-Desktop und klicken auf die Ansicht Dateien
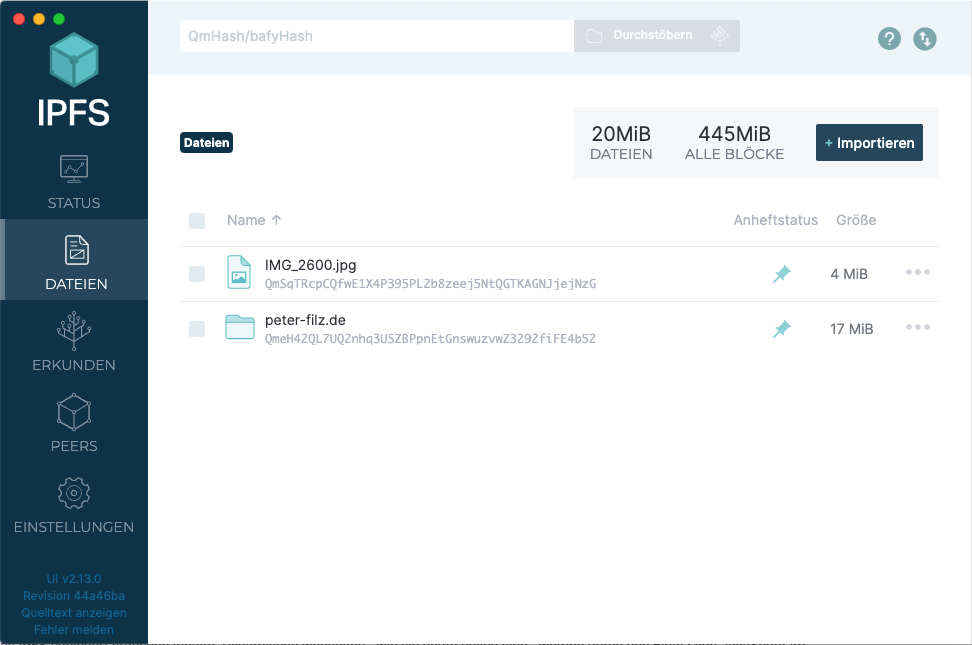
Wir klicken auf +Importieren und dann wählen wir Ordner. Nun könnne wir unseren Ordner, der die Webseite beeinhaltet, auswählen und der gesamte Ordnerinhalt wird in das IPFS geladen.
Danach sehen wir den Ordner in der Dateiliste. Mit Klick auf die drei senkrechten Punkte öffnen wir ein Menü. Dort können wir die CID kopieren. Das ist nun die Adresse unserer Webseite im IPFS.
Wie wir auch eine ganz normale Domain nutzen können, erkläre wich weiter unten.
Die Webseite im IPFS wieder abrufen
Es gibt grundsätzlich 2 Möglichkeiten, die Webseite wieder abzurufen. Da wir einen eigenen Node betreiben und auch den IPFS-Companion in Chrome installiert haben, können wir in die Browsezeile in Chrome einfach diese Adressformt eingeben:
ipfs//QmSqTRcpCQfwE1X4P395PL2b8zeej5NtQGTKAGNJjejNzG
Danach werden wir um die Zustimmung einer Weriterleitung gebeten und wir rufen die Webseite von unserem eignenen Node wieder ab.
Die Webseite über ein IPFS-Gateway wieder abrufen
Wer noch im alten Web surft und keinen eigenen IPFS-Node betreibt, soll natürlich auch Zugriff auf unsere Seite erhalten. Er kann im herkömmlichen Web eines der zahlreichen Gateways verwenden.
Die Webadresse für das Gateway von ipfs.io wäre dann diese, wobei die Adresse am Ende des URLS entsprechend angepasst werden muss:
https://ipfs.io/ipfs/Qme7ss3ARVgxv6rXqVPi........
Vorsicht: Öffnet man eine solche URL nun in Chrome, so wird Chrome erkennen, dass wir eine IPFS-Adresse anfordern und diese Einfach direkt vom lokalen Node holen (und eben nicht über das Gateway).
Will man das Gateway ausprobieren, so nutzt man dafür am besten einen anderen Browser.
Webseite dauerhaft speichern
Die Webseite ist nun auf unserem Node gespeichert. Wenn wir nun eine Weile Dateien im IPFS abrufen, werden auch diese auf unserem Node gespeichert. Irgendwann kommt der Zeitpunkt, da wird unser Node aufräumen und ältere Dinge löschen - möglicherweise auch unsere Webseite.
Damit das nicht passiert, können wir die Seite auf unserem Node pinnen oder in Deutsch anheften. Wir klicken auf die drei Punkte ganz hinten in der Zeile mit dem Verzeichnisnamen und wählen Anheften einstellen aus. Nun können wir unsere Webseite pinnen und sie wird zumindest auf unserem Node nicht mehr gelöscht.
Webseite dauerhaft erreichbar machen
Wir sind im Moment vermutlich die einzigen, die unsere Seite abrufen. Dadurch verteilt sie sich nicht auf andere Nodes. Somit ist sie nur bei uns lokal gespeichert. Solange unsere Node läuft, ist die Seite erreichbar. Schalten wir die Node ab, ist die Webseite verschwunden.
Zum Glück gibt es Dienste, die IPFS-Nodes dauerhaft betreiben. Ich empfehle ein kostenfreies Konto bei Pinata zu eröffnen. Hier ist 1 GB IPFS-Node-Speicherplatz im kostenfreien Paket enthalten.
In Pinata kann man ebenfalls das geamte Verhzeichnis, dass die Webseite enthält, hochladen.
Das pinnen dauert dann einen Momant. Danach kann man die Webseite dauerhaft im IPFS abrufen. Und jeder, der sie abruft, sorgt dafür, dass sie noch etwas mehr verteilt gespeichert wird.
Achtung: Versucht man die Webseite über das Gateway von Pinata wieder abzurufen, so geht das bei größeren webseiten schief. Pinata hat ein Limit von Abfragen in einem bestimmten Zeitraum. Eine größere Webseite ruft beim Seitenaufbau viele Dateien ab und erreicht dadurch schnell das Limit. Dann fehlen plötzlich Bilder und CSS-Dateien. Der Seitenabruf sollte also immer über ein anderes Gateway passieren.
Eine anständige Domain für die Webseite
Die cryptische HASH-Adresse kann man sich natürlich nicht merken. Ausserdem führt jede Änderung zu einem neuen HASH-Wert und somit zu einer neuen Adresse. Wäre es da nicht besser, wenn man die letzte Version der Seite immer unter einer Adresse wie ipfs://peter-filz.de erreichen könnte?
Voraussetzung dafür ist, dass man die betreffende Domain besitzt und diese auch konfigurieren darf. Ist das der Fall, geht man bei seinem Domain-Provider in die Domain-Verwaltung und fügt einen Txt-Record mit diesen Parametern hinzu:
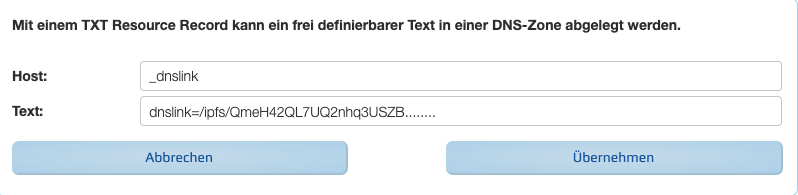
Am Ende des Textes muss natürlich die korrekte IPFS-Adresse eingesetzt werden.
Nach dem Speichern kann es eine Weile dauern, bis der Eintrag durchrepliziert ist und auch wirklich funktioniert. Auch hier ist etwas Gedud gefragt.
Webseite aktualisieren
Leider müssen wir, wann immer wir die Seite ändern, eine neue Version ins IPFS laden. Dort bekommt sie eine neue Adresse, die wir dann wiederum in den Domain-Einstellungen eintragen müssen. Nach einiger Zeit, ist dann die neue Seite erreichbar.
Wenn man den Domain-Eintrag erst ändert, wenn die neue Seite wirklich im IPFS verfügbar ist, entstehen auch keine Unterbrechungen in der Erreichbarkeit der Seite.